![]()
情欲印象qvod 北交开源o1代码版!强化学习+蒙特卡洛树搜索
发布日期:2024-12-09 22:03 点击次数:59

北京交通大学洽商团队悄默声推出了一版o1情欲印象qvod,况且通盘源代码、精选数据集以及生息模子皆开源!
名为O1-CODER,专注于编码任务。
团队合计编码是一个需要System-2想维边幅的典型任务,波及严慎、逻辑、一步步的问题处罚流程。
而他们的战略是鉴定化学习(RL)与蒙特卡洛树搜索(MCTS)相联结,让模子大要束缚生成推理数据,晋升其System-2智商。
实验中,团队有以下几点要道发现:
当推理正确时,基于伪代码的推理权贵晋升了代码生成质料
将监督微调(SFT)与平直偏好优化(DPO)相联结大要晋升测试用例生成后果
自我对弈强化学习为推理和代码生成创造了不息改动的轮回机制
具体来说情欲印象qvod,团队聘用了测试用例生成器,在经过DPO后达到89.2%的通过率,比拟运转微调后的80.8%有权贵晋升;Qwen2.5-Coder-7B聘用伪代码要领竣事了74.9%的平均采样通过率,晋升了25.6%。
网友直呼很需要这么的模子。

O1-CODER,究竟长啥样?

六步,迟缓优化o1
应用于代码生成的自我对弈强化学习靠近两大挑战:
收尾评估,即如何评判生成代码的质料。与围棋等任务不同,评估代码需要在测试环境中运行并考证。
界说想考和搜索步履,即细目流程奖励的对象和粒度。
关于第一个挑战,团队提议考研一个测试用例生成器(TCG),左证问题和尺度代码自动生成测试用例,为强化学习提供尺度化的代码测试环境和收尾奖励。
关于第二个挑战,他们选择”先想考后行径“的边幅:先通过详备的伪代码想考问题,再基于伪代码生成最终的可现实代码。
这种边幅的上风在于适合性(兼并伪代码可对应不同的具体竣事)和可控粒度(通过调度伪代码的细节进程畛域推理/搜索步履的粒度)。
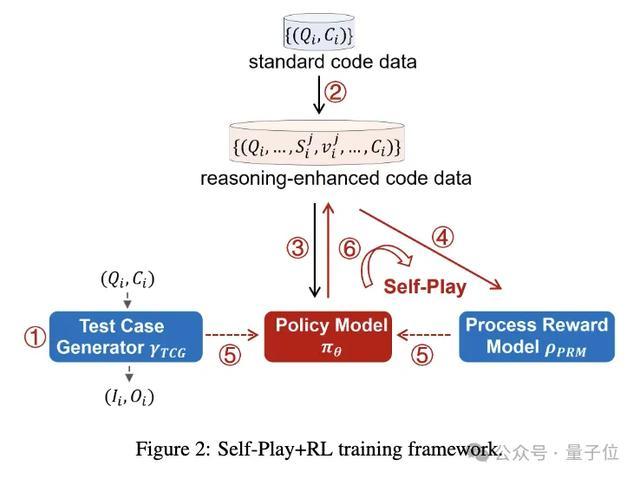
具体来说,洽商团队提议了一个包含六个门径的框架:
考研测试用例生成器(TCG),为代码测试提供尺度化的环境
欺诈MCTS生成包含推理流程的代码数据
迭代微调战略模子,先生成伪代码,再生成完好代码
基于推理流程数据运转动流程奖励模子(PRM)
在TCG提供的收尾奖励和PRM提供的流程奖励的双重斥地下,通过强化学习和MCTS更新战略模子
欺诈优化后的战略模子生成新的推理数据,复返第4步迭代考研
两阶段考研测试用例生成器
在实验部分,洽商东谈主员详备先容了测试用例生成器的考研流程。
分为两个阶段:监督微调(SFT)和平直偏好优化(DPO)。
SFT阶段的主要标的是确保生成器的输出恰当预界说时势,以便准确分解和索取生成的测试用例。考研数据来自TACO数据集。

DPO阶段的标的是斥地模子生成恰当特定偏好的测试用例,进一步提高生成器的性能和可靠性。
这里聘用了带有东谈主工构建样本对的DPO要领,构建了一个偏好数据集。
实验标明,SFT阶段事后,TCG在尺度代码上生成的测试用例通过率达到80.8%,DPO阶段进一步晋升至89.2%,大幅改善了生成器产出可靠测试用例的智商。
伪代码推理,斥地模子进行深度推理
卓越值得一提的是,洽商者引入了基于伪代码的辅导要领,将其看成斥地模子进行深度推理的“默契器用”。
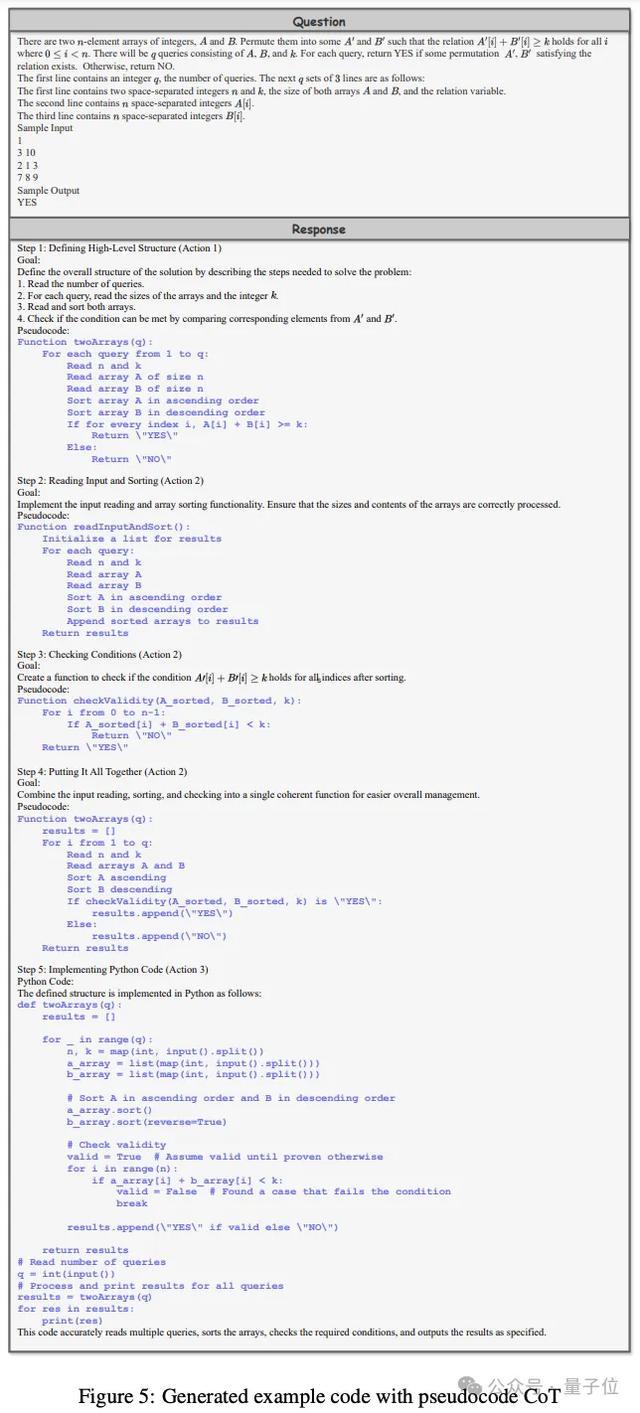
他们为此界说了三个要道步履:
使用伪代码界说算法结构:勾画主要函数的结构和接口,把合手任务的合座框架
细化伪代码:迟缓明确每个函数的具体门径、逻辑和操作
从伪代码生成代码:将伪代码的结构和逻辑精确翻译为可现实代码

在MBPP数据集上进行的初步实验标明,尽管合座通过率(Pass@1)有所着落,但Average Sampling Pass Rate(ASPR)权贵提高。

标明联结伪代码权贵改善了推理流程的质料,卓越是在细化通向正确输出的旅途方面。这为后续的自监督微调和强化学习提供了致密的伊始。
自我对弈+强化学习
洽商东谈主员详备姿色了如何使用蒙特卡洛树搜索(MCTS)来构建门径级别的流程奖励数据。
这个流程波及到为每个问题造成一个推理旅途,该旅途由一系列推理门径构成,并最终产生一个可现实的代码。在MCTS的旅途探索中,使用伪代码辅导战略来斥地推理流程。当达到末端节点时,就造成了一个完好的伪代码推理旅途。
末端节点的奖励值是基于两个要道盘算计较的:编译见效能(compile)和测试用例通过率(pass)。
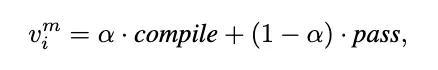
这些盘算被用来评估生成的代码的质料和正确性。
奖励值被反向传播到旅途上的通盘前序节点,为每个门径分派一个奖励值。通过这种边幅,构建了推理流程数据集,为战略模子的运转动和考研提供了基础。
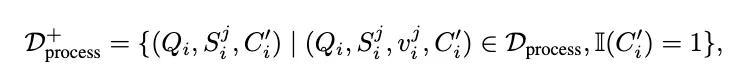
流程奖励模子(PRM)的任务是为现时门径分派一个奖励值,以预见其对最终谜底的孝敬。
在数据合成流程中使用的树搜索要领不错组织成点式(point-wise)和成对式(pair-wise)两种数据时势。

基于这些经过考证的正确推雄厚,战略模子取得运转动。
接下来,流程奖励模子(PRM)出手发达作用,评估每一步推理对最终谜底的孝敬。在测试用例生成器(TCG)提供的收尾奖励和PRM提供的流程奖励的双重斥地下,战略模子通过强化学习束缚改动。
更新后的战略模子被用来生成新的推理数据,补充到现存数据聚会,造成自我对弈的闭环。这个数据生成-奖励建模-战略优化的迭代轮回,确保了系统推奢睿商的不息晋升。
偷窥色片— 完 —情欲印象qvod
上一篇:奇米影视盒下载 华为助力北京经开区打造Yi格式政务数据料理和政务数字化转型典范 下一篇:奇米影视盒下载 出院三天收到生养津贴!临沂产妇在济南生宝宝,体验“落地参保”